pip install scrapy -i
注:推荐使用anaconda安装,conda install scrapy



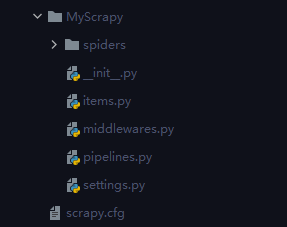
cd MyScrapy
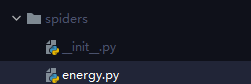
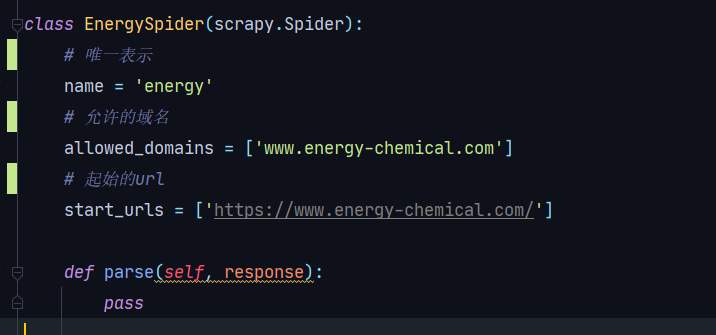
scrapy genspider energy www.energy-chemical.com

 pycharm远程连接到服务器
pycharm远程连接到服务器
 pycharm更改字体大小
pycharm更改字体大小